Python 3 Tutorial: How to Rotate Proxies and IP Addresses
In web crawlers and automated tasks, frequent use of the same IP address may lead to the blocking of the target website. This article will explain how to implement proxy and IP rotation with Python 3 through 3 mainstream solutions, and provide detailed code implementation and pitfall avoidance guide.
Basic proxy rotation solution (Requests library)
1. Prepare proxy pool
proxies_pool = [
{"http": "http://123.45.67.89:8080", "https": "http://123.45.67.89:8080"},
{"http": "http://112.233.44.55:3128", "https": "http://112.233.44.55:3128"},
# Expandable with more proxies...
]
2. Implement random rotation
import requests
import random
from time import sleep
def rotate_proxy_request(url):
while True:
try:
proxy = random.choice(proxies_pool)
response = requests.get(
url,
proxies=proxy,
timeout=10,
headers={"User-Agent": "Mozilla/5.0"}
)
if response.status_code == 200:
return response.text
except Exception as e:
print(f"proxy {proxy} fail: {str(e)}")
sleep(2) # Delayed retry after failure
# Usage Examples
data = rotate_proxy_request("https://target-website.com/data")
3. Key parameter description
timeout: Set timeout to avoid long waiting timeException capture: Automatically switch to the next proxy
User-Agent rotation: It is recommended to rotate with header information
Advanced rotation scheme (Scrapy middleware)
1. Configure middleware
# middlewares.py
import random
class ProxyMiddleware:
def process_request(self, request, spider):
proxy = random.choice(proxies_pool)
request.meta['proxy'] = proxy['http']
# Add when authentication is required
# request.headers['Proxy-Authorization'] = basic_auth_header('user', 'pass')
2. Modify settings.py
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.ProxyMiddleware': 543,
}
Browser Automation Solution (Selenium + Proxy)
1. Chrome Proxy Configuration
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
def get_chrome_with_proxy(proxy):
chrome_options = Options()
chrome_options.add_argument(f'--proxy-server={proxy}')
driver = webdriver.Chrome(options=chrome_options)
return driver
# Usage Examples
driver = get_chrome_with_proxy("123.45.67.89:8080")
driver.get("https://target-site.com")
Notes and optimization suggestions
1. Proxy quality selection
High-anonymous proxy vs. transparent proxy
Recommend paid proxy services (such as Swiftproxy)
Free proxy needs to verify validity
2. Validity verification module
def validate_proxy(proxy):
try:
test = requests.get(
"http://httpbin.org/ip",
proxies=proxy,
timeout=5
)
return test.json()['origin'] in proxy['http']
except:
return False
3. Intelligent switching strategy
Dynamically adjust priority based on response time
Automatically eliminate failures based on threshold
4. Legal compliance
Comply with robots.txt protocol
Control access frequency (recommended ≥5 seconds/time)
Comparison of expansion solutions
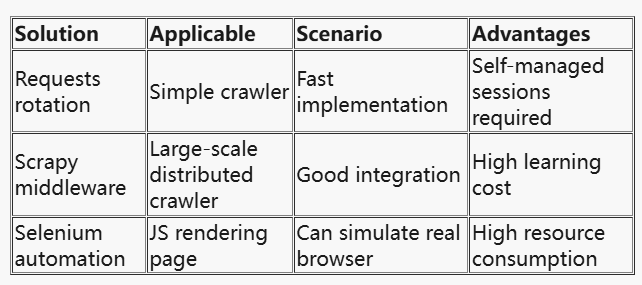
Conclusion
Through the above solutions, developers can choose the appropriate proxy rotation strategy according to specific needs. It is recommended to use paid proxy services in production environments and cooperate with the health check mechanism to ensure the quality of the proxy pool. Pay attention to setting the request interval reasonably and comply with network ethics.